WonJun Moon1 ·
Jae-Pil Heo2
1KAIST 2Sungkyunkwan University
Official PyTorch implementation of SSync (Selective Synergistic Learning), a selective mutual-distillation framework for video object-centric learning.
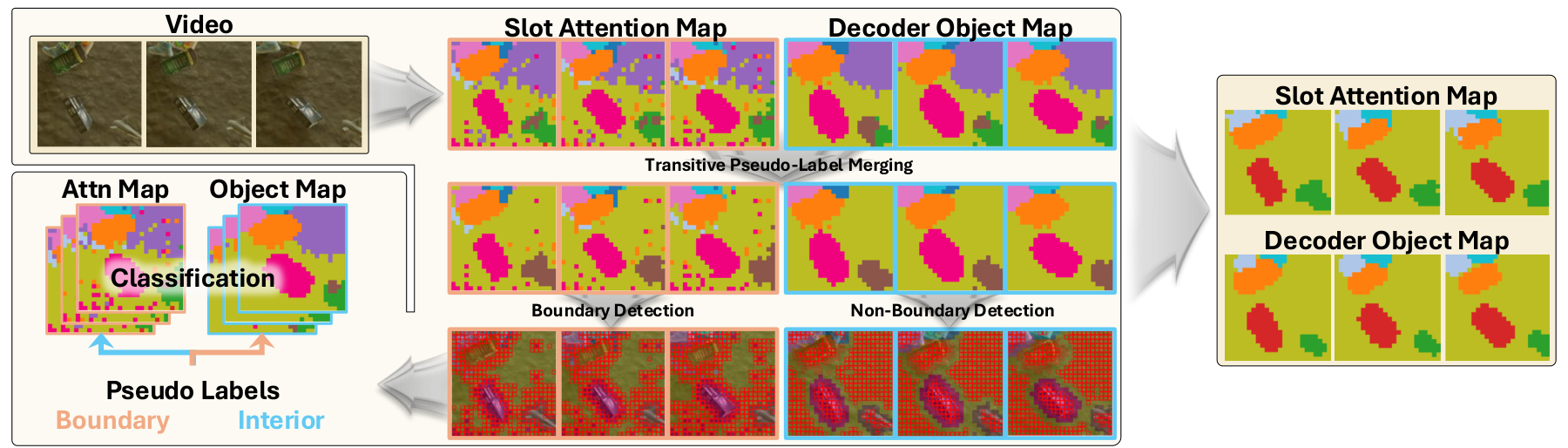
Typical video object-centric learning (VOCL) approaches employ slot-based frameworks that rely on reconstruction-driven encoder–decoder architectures, where learning is mediated by two spatial maps: attention maps from the encoder and object maps from the decoder. As these two distinct maps exhibit different properties, a recent dense alignment strategy attempted to reconcile this discrepancy by enforcing agreement across all spatio-temporal patches via contrastive learning. However, this indiscriminate alignment inadvertently propagates the inherent weaknesses of each module, such as noisy encoder predictions and blurred decoder boundaries. Moreover, computing dense similarities across all pairs incurs a computational cost quadratic in the total number of spatio-temporal patches, severely limiting scalability.
Motivated by this, we propose Selective Synergistic Learning (SSync). Instead of exhaustive patch-to-patch alignment, SSync prevents error propagation by selectively distilling only the most reliable cues: leveraging the encoder strictly for boundary refinement and the decoder for interior denoising. This is realized via pseudo-labeling with linear complexity, eliminating the need for quadratic spatial comparisons. Also, to prevent the reinforcement of architectural biases like slot redundancy, we introduce a transitive pseudo-label merging that consolidates overlapping slots based on spatio-temporal activation consistency. Extensive studies demonstrate that SSync improves decomposition quality and serves as a versatile, plug-and-play module while also exhibiting exceptional robustness to slot configurations.
pip install poetry
poetry lock
poetry install
poetry run pip install matplotlib coco notebook
poetry run pip install tensorboard tensorboardXTo download the datasets used in this work, see the instructions in data/README.md.
For more details, we refer to the SlotContrast repository.
The datasets should be placed under a common root directory with the following structure:
├── SlotCurri/
└── dataset/
├── ytvis2021_resized/
├── movi_c/
└── movi_e/
| Dataset | Download | Size |
|---|---|---|
| YouTube-VIS 2021 | Google Drive | 26.43 GB |
| MOVi-C | Google Drive | 7.43 GB |
| MOVi-E | Google Drive | 8.26 GB |
Run one of the configurations in configs/SSync, for example:
poetry run python -m SSync.train --run-eval-after-training configs/SSync/coco.yaml
poetry run python -m SSync.train --run-eval-after-training configs/SSync/movi_c.yaml
poetry run python -m SSync.train --run-eval-after-training configs/SSync/movi_e.yaml
poetry run python -m SSync.train --run-eval-after-training configs/SSync/ytvis2021.yaml| Dataset | Download |
|---|---|
| MOVi-C | Google Drive |
| MOVi-E | Google Drive |
| YouTube-VIS 2021 | Google Drive |
| COCO 2017 | Google Drive |
Each clip blends the original input with the predicted slot map (each object in a distinct color). For interactive controls, visit the project page.
| MOVi-C | MOVi-E | YouTube-VIS 2021 |
|---|---|---|
If you find this work useful, please consider citing:
@inproceedings{moon2026ssync,
title = {Selective Synergistic Learning for Video Object-Centric Learning},
author = {Moon, WonJun and Heo, Jae-Pil},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}as well as SlotCurri and SRL:
@inproceedings{moon2026reconstruction,
title = {Reconstruction-Guided Slot Curriculum: Addressing Object Over-Fragmentation in Video Object-Centric Learning},
author = {Moon, WonJun and Seong, Hyun Seok and Heo, Jae-Pil},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}
@inproceedings{seong2026synergistic,
title = {From Vicious to Virtuous Cycles: Synergistic Representation Learning for Unsupervised Video Object-Centric Learning},
author = {Seong, Hyun Seok and Moon, WonJun and Heo, Jae-Pil},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026}
}Our implementation is built upon the official repositories of VideoSAUR, SlotContrast, SRL, and SlotCurri.
This codebase is released under the MIT License. Some parts of the codebase were adapted from other codebases; a comment was added to the code where this is the case, and those parts are governed by their respective licenses.