

____ _ _ _ _ _ / ___| (_) _ __ ___ _ __ | |__ | | __ _ | |__ | | __ _ \___ \ | || '_ \ / _ \| '_ \ | '_ \ | | / _` || '_ \ | | / _` | ___) || || | | || __/| | | || | | || || (_| || | | || || (_| | |____| |_||_| |_| \___||_| |_||_| |_||_| \__,_||_| |_||_| \__,_| ___ _ _ _ _ _ _ / _ \ (_) _ __ (_) ___ ___ | \ | || | __ ___ ___ (_) | | | || || '_ \ | |/ __| / _ \ | \| || |/ // _ \ / __|| | | |_| || || | | || |\__ \| (_) | | |\ || <| (_) |\__ \| | \__\_\|_||_| |_||_||___| \___/ |_| \_||_|\_\\___/ |___/|_|
Java Developer | FNB Enablement Office of the CIO
Honours in Computer Science | University of Pretoria
I enjoy designing and building backend systems, enterprise applications, and data-driven solutions that address real-world problems.
This is where I document both sides of that work.
| Focus Area | Tech Stack |
|---|---|
| Enterprise Backend | Java, Spring Boot, REST APIs, Microservices, Database Design |
| Cloud & Infrastructure | Docker, Kong API Gateway, Prometheus, Grafana, ELK Stack |
| Machine Learning | NLP, Cross-lingual Embeddings, Time-Series Forecasting, Model Evaluation |
| Data Engineering | Python, Pandas, NumPy, scikit-learn, Streamlit |
| Full-Stack Development | HTML5, CSS3, JavaScript, Responsive Design |
| Area | Technologies & Concepts | Representative Projects |
|---|---|---|
| Java & Enterprise Development | Java, Spring Boot, REST APIs, Enterprise Application Design | Cloud-Sim Bank, Enterprise Microservices |
| Cloud & Infrastructure | Docker, API Gateways, Monitoring & Logging, Distributed Systems Concepts | Cloud-Sim Bank |
| Machine Learning & NLP | FastText, Cross-Lingual Embeddings, Time-Series Forecasting, Model Evaluation | Cross-Lingual Embeddings, Electricity Demand Forecasting |
| Data & Analytics | Python, Pandas, Power BI, Streamlit, Statistical Analysis | Demand Dashboard, Analytics Projects |
| Web Development | HTML5, CSS3, JavaScript, Responsive Design | SA Taxi Platform, Student Dashboard |
Working on strengthening my understanding of enterprise software architecture, distributed systems, observability practices, and modern Java development while applying these concepts in a banking technology environment.
Repository: youth_cloud_banking_system
A microservices-based banking platform developed to explore modern enterprise architecture patterns. The project demonstrates service-to-service communication, API gateway integration, centralized monitoring, logging, and independent service deployment within a distributed system.
System Architecture:
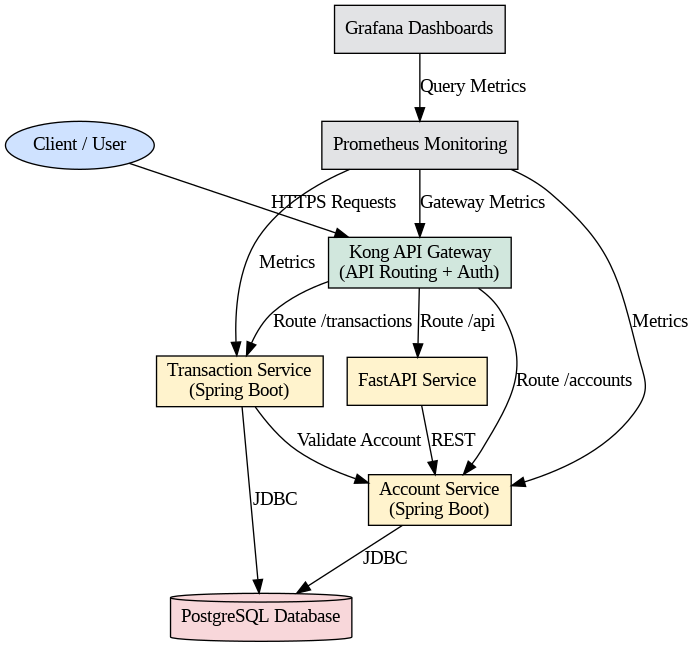
How It Works:
Client
│
├─ Kong API Gateway (8000)
│ - Request routing
│ - Rate limiting
│ - Authentication
│
├─ Account Service (8081)
│ - User management
│ - Account operations
│
├─ Transaction Service (8082)
│ - Deposits/Withdrawals
│ - Transfer logic
│
└─ PostgreSQL (5432)
- Persistent storage
- ER modeled schema
Observer Layer:
• Prometheus (9090) → Metrics collection
• Grafana (3000) → Dashboard visualization
• ELK Stack (9200, 5601) → Centralized logging
Component Breakdown:
| Component | Purpose | Technology |
|---|---|---|
| API Gateway | Routes requests, enforces policies | Kong |
| Account Service | Manages user accounts and operations | Java Spring Boot |
| Transaction Service | Processes banking transactions | Java Spring Boot |
| Database | Data persistence | PostgreSQL |
| Metrics | System observability | Prometheus + Grafana |
| Logs | Centralized log aggregation | Elasticsearch, Logstash, Kibana |
What's Actually Running:
Prometheus collecting metrics from all services:
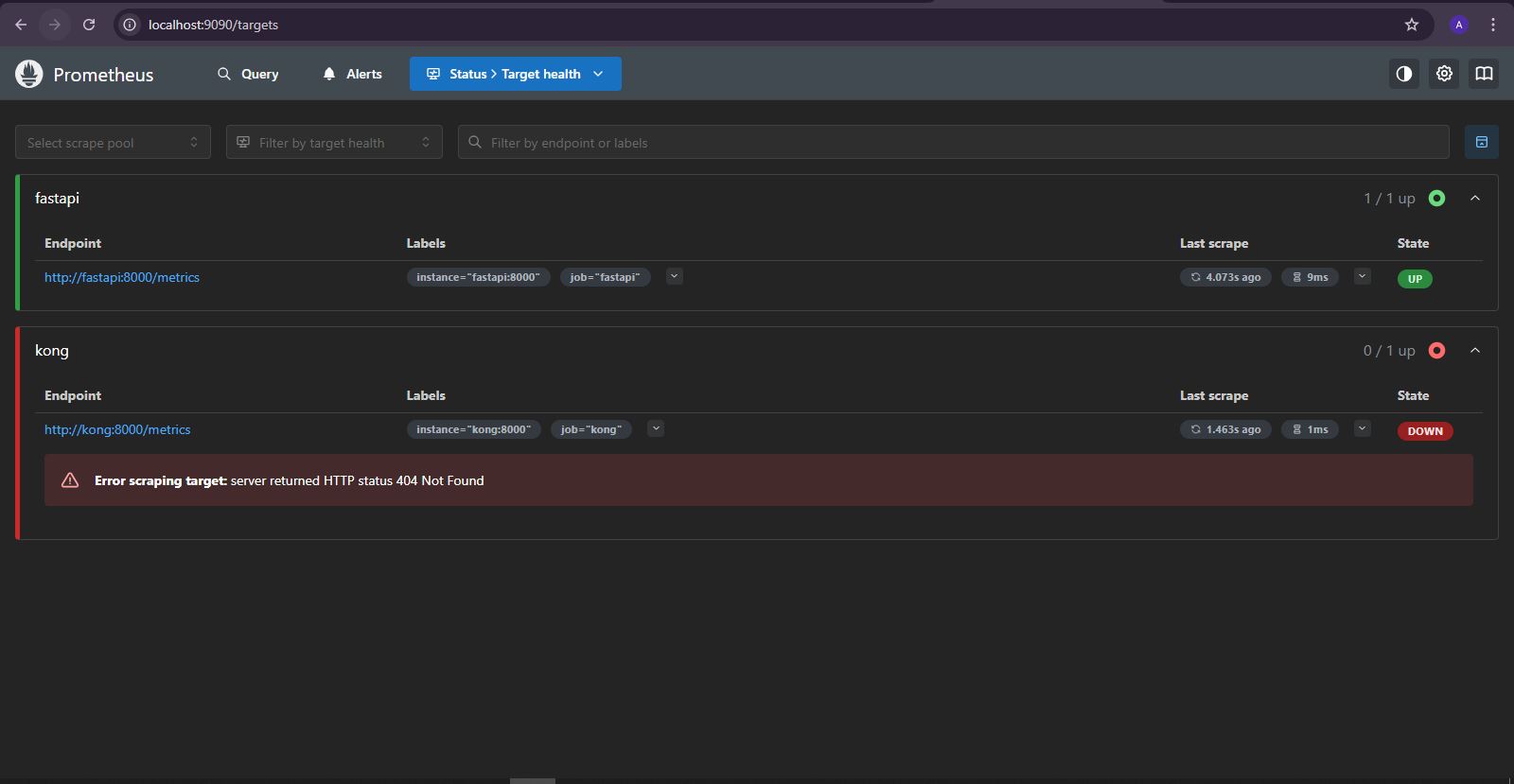
All services reporting metrics successfully
Grafana dashboards showing throughput, latency, and health:
Real-time metrics: request throughput, response latency, service health
Kibana making logs searchable across all services:
Centralized logs for debugging and compliance
Why This Approach Matters:
When you separate concerns like this, each service can be developed, tested, and deployed independently. The API gateway handles cross-cutting concerns like authentication and rate limiting. Monitoring is built in from the start, not bolted on later. When something breaks, you have metrics and logs to understand what happened. This is how modern systems work at scale.
Repository: Cross-Lingual-Embeddings-NLP-2026
An honours research project investigating a real problem: how do you build NLP systems for languages that don't have large amounts of digital training data?
The Challenge:
Most AI models perform well on English because there's abundant training data. South Africa has 11 official languages. If technology can't understand them, it can't serve the people who speak them. This project explores cross-lingual embeddings where knowledge learned from one language transfers to another.
Why This Work Matters:
Language is inseparable from culture and identity. If AI systems only work in English, they encode a particular worldview. This research contributes to making machine learning more inclusive and ensuring technology can serve diverse communities.
What We Did:
- Trained FastText embeddings for isiZulu, Sepedi, and Setswana
- Used orthogonal Procrustes mapping to align semantic spaces across languages
- Evaluated alignment quality through bilingual lexicon induction and downstream tasks
- Analyzed what makes alignment work (morphological similarity, vocabulary overlap, etc.)
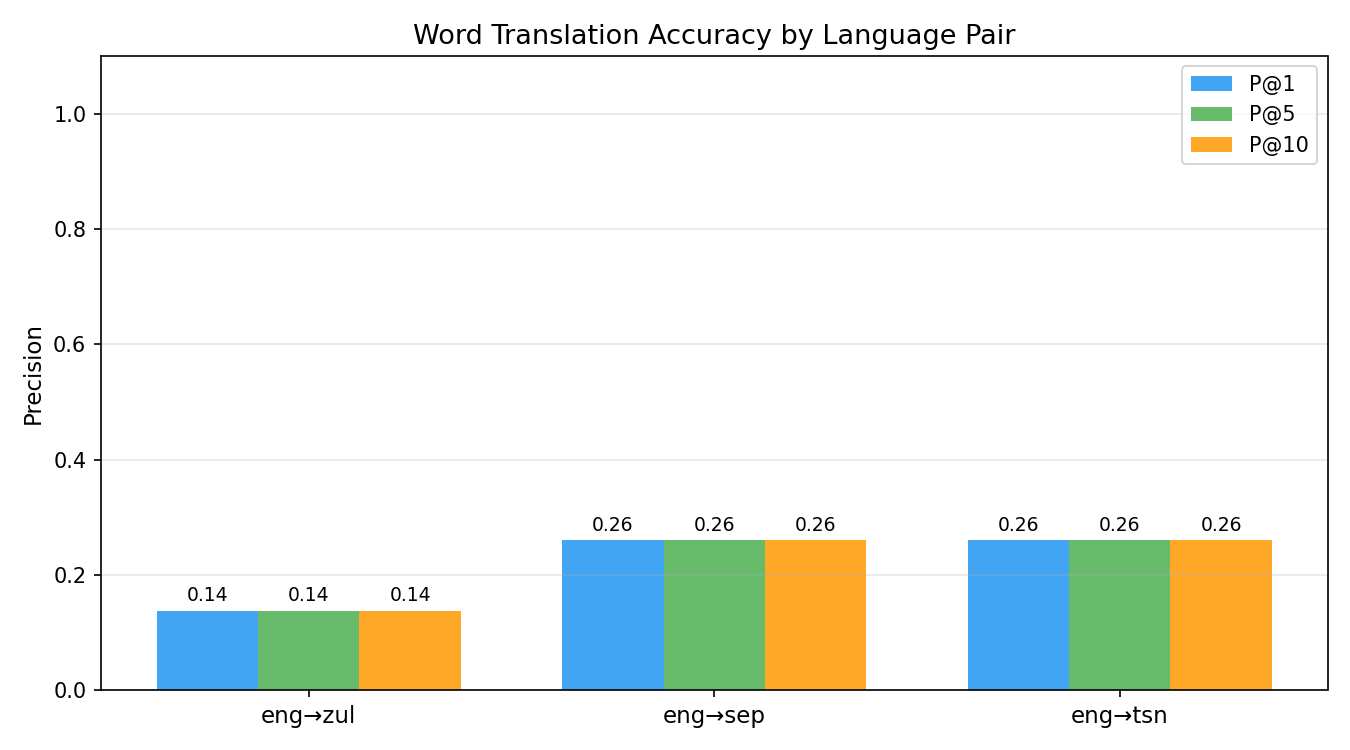
Results Across Alignment Strategies:
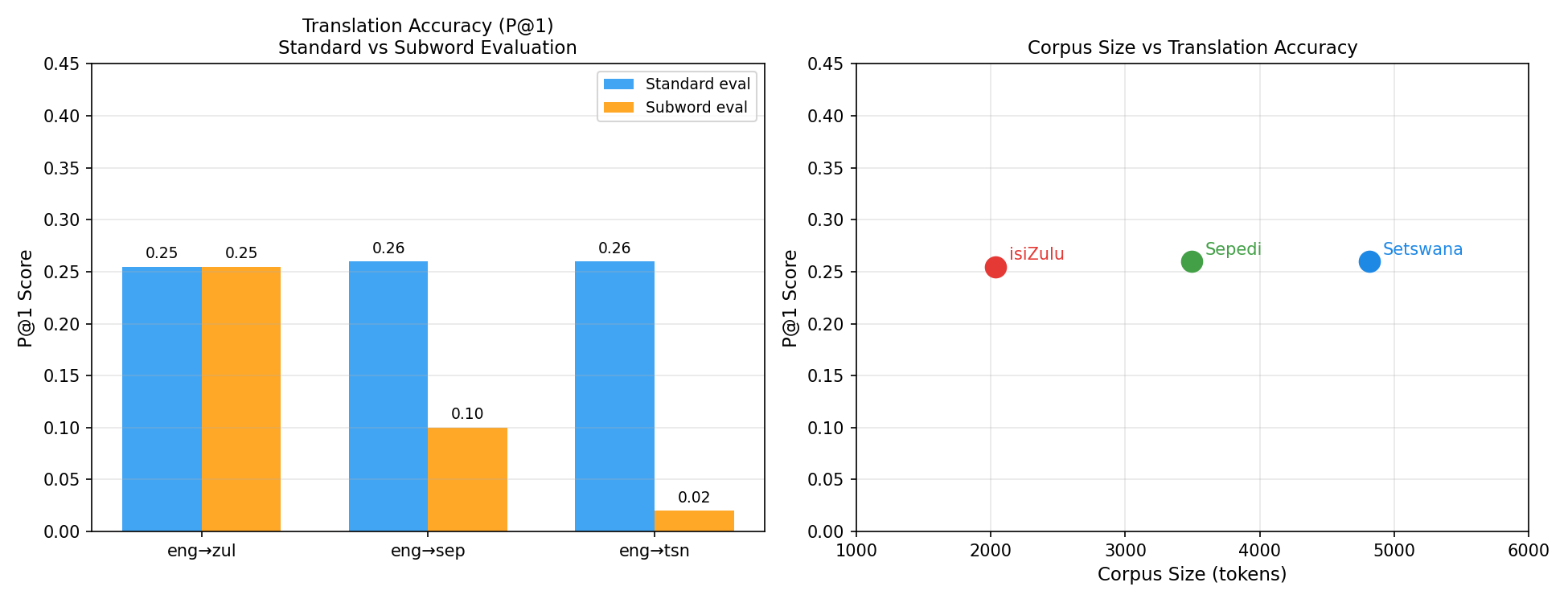
Final performance metrics across all alignment strategies
Strategy Comparison Between Languages:
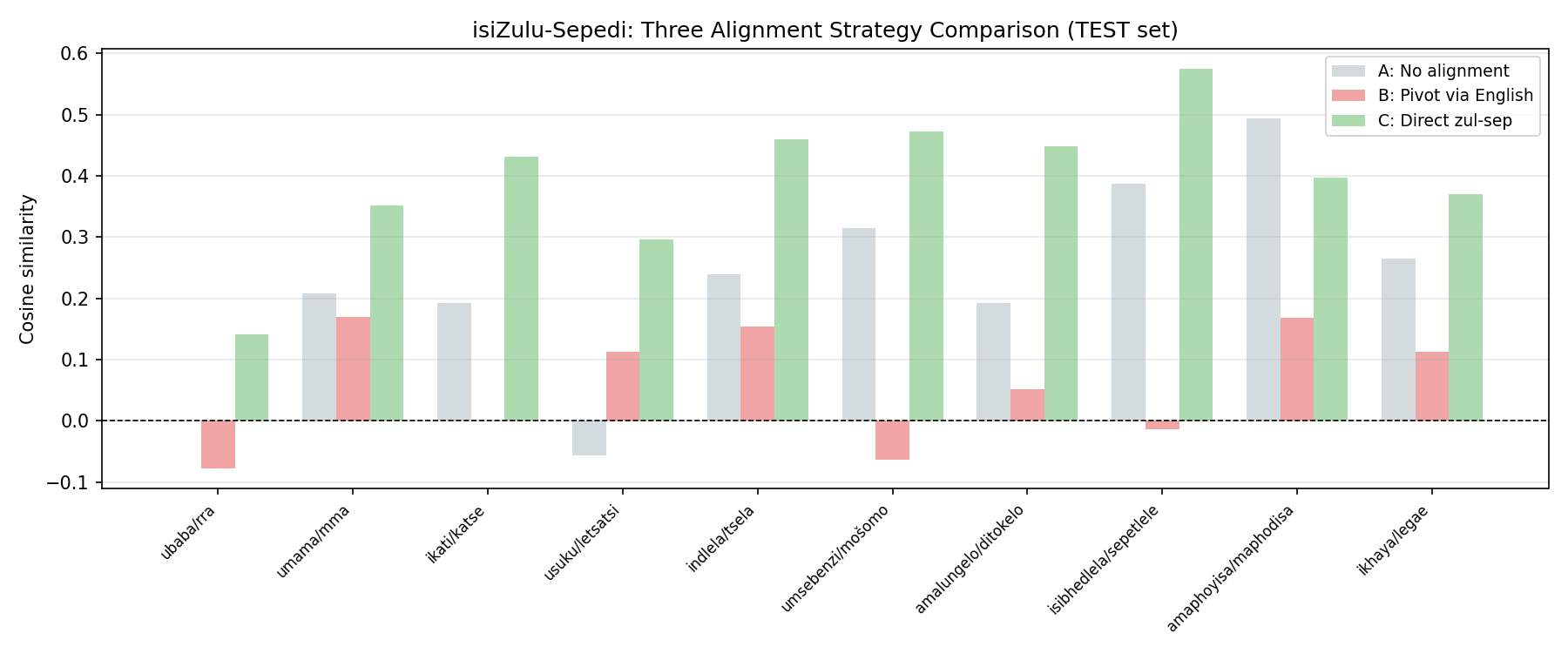
Comparing different embedding alignment techniques
Morphological Similarity Matters:
Words that look similar across languages align better
Visualizing the Semantic Space (t-SNE):
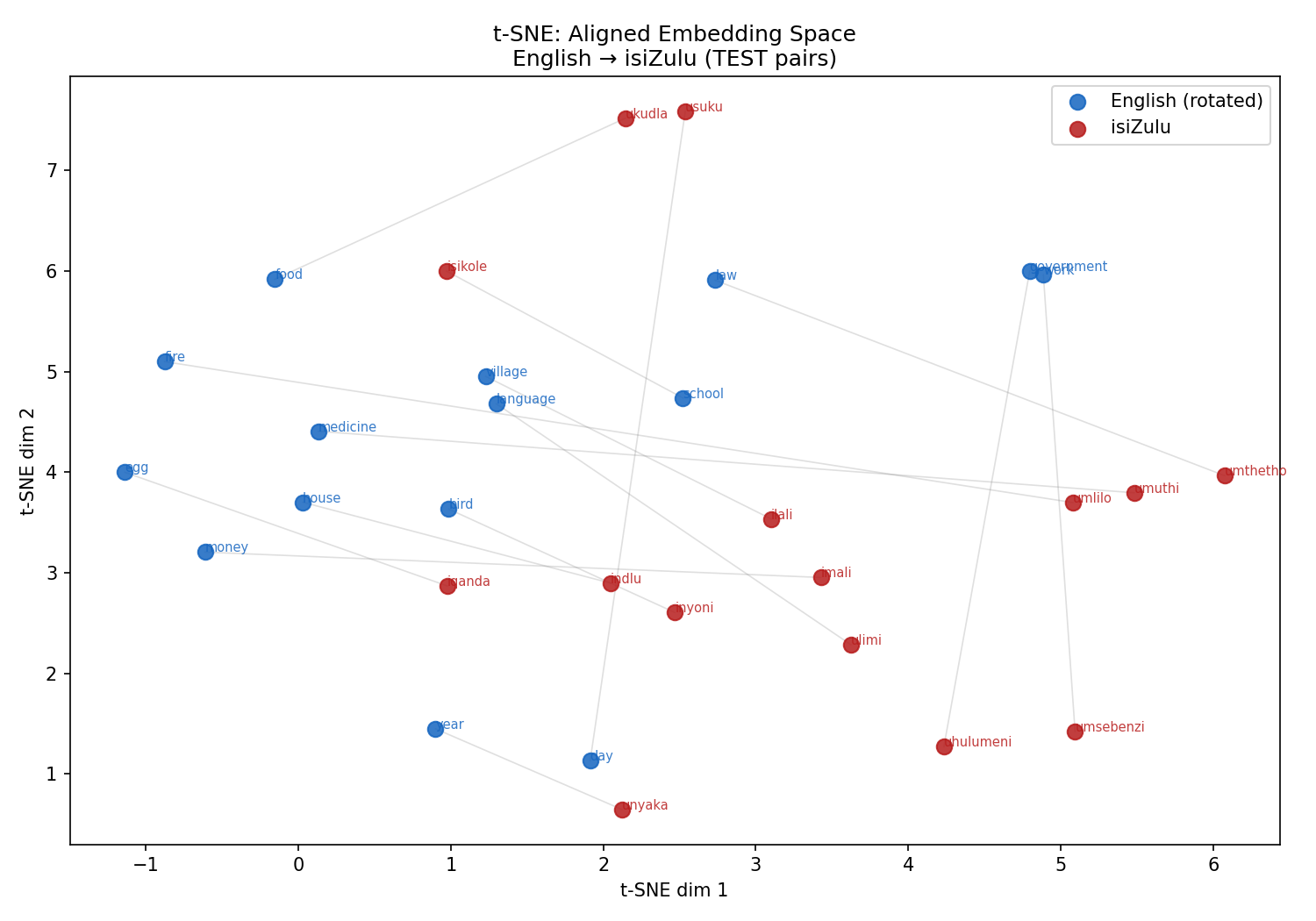
How English and isiZulu semantic spaces align after Procrustes mapping
Key Findings:
- Orthogonal Procrustes mapping creates stable, meaningful alignments
- Morphologically similar languages transfer knowledge better
- Just a few hundred bilingual word pairs can bootstrap high-quality embeddings
- Anchor words act as bridges between semantic spaces
Time-series forecasting model predicting electricity demand using temperature and temporal variables. Achieves strong accuracy on multi-step forecasts.
Key Achievement: ARIMAX model outperforms ARIMA baseline by 23% when including exogenous variables.
Data & Analytics
- Eskom Load Shedding Impact Analysis (Streamlit dashboards)
- Youth Unemployment Analysis (Power BI visualizations)
Machine Learning
- Graduate Prediction Models (Random Forest classification)
- Model and Bias Audit (fairness evaluation)
Full-Stack Applications
- SA Taxi Platform (fares, routes, seat selection, QR payments)
- Smart Clinic Management System
- Student Dashboard with NFC functionality
Backend Infrastructure
├─ Java & Spring Boot
├─ REST API design
├─ Microservices architecture
└─ System design
Data & Analysis
├─ Python data stack
├─ Statistical modeling
├─ Time-series forecasting
└─ ML pipeline development
Operations
├─ Docker containerization
├─ Prometheus monitoring
├─ Grafana dashboards
├─ ELK stack logging
└─ Kong API gateway
Language & NLP
├─ FastText embeddings
├─ Cross-lingual alignment
├─ Gensim toolkit
└─ Evaluation methodologies
Start with understanding. What's the actual problem? What constraints exist? What does success look like?
Design for people. Not just now, but how this system will grow and how teams will collaborate on it.
Build observability in. Monitoring, logging, and metrics from day one. You can't fix what you can't see.
Document the reasoning. Why this approach? What were the tradeoffs? What might we change next time?
Learn and iterate. Each project teaches something. I carry those lessons forward.
Built with intention. Crafted with care.
Continuously learning, building, and improving