



NeMo Curator helps ML engineers and data teams build repeatable, GPU-accelerated pipelines that load, filter, deduplicate, and transform large text, image, video, and audio datasets for AI training. Run the same pipeline on a laptop or across a multi-node Ray cluster.
Part of the NVIDIA NeMo software suite for managing the AI agent lifecycle.
- 2026-04 — NeMo Curator 26.04: Cosmos-Xenna 0.2.0 upgrade, simplified
ResourcesAPI, Ray runtime upgrade. See the release notes. - 2026-02 — NeMo Curator 26.02: Ray-based pipeline architecture for all modalities — text, image, video, and audio.
| Modality | Common Operations | Guide |
|---|---|---|
| Text | Deduplication, classification, quality filtering, language detection | Text Guide |
| Image | Aesthetic filtering, NSFW detection, embedding generation, deduplication | Image Guide |
| Video | Scene detection, clip extraction, motion filtering, deduplication | Video Guide |
| Audio | ASR transcription, quality assessment, WER filtering | Audio Guide |
- You need repeatable curation pipelines — not one-off notebooks or ad-hoc scripts.
- You need GPU and distributed execution for data-heavy stages (dedupe, classification, embedding, inference).
- You need modality-aware building blocks for text, image, video, or audio.
- You want recipes that map to NVIDIA training workflows like Nemotron and Nemotron-CC.
Three paths, depending on what you're trying to do. Each path is self-contained.
NeMo Curator uses uv for installation. Install it once:
curl -LsSf https://astral.sh/uv/install.sh | shVerify your environment and run a tiny text pipeline.
uv venv && source .venv/bin/activate
uv pip install "nemo-curator[text_cpu]"
python -c "import nemo_curator; print(nemo_curator.__version__)"The bundled quickstart starts Ray, downloads a Hugging Face model, and runs a sentiment classification pipeline on GPU.
Prerequisites: CUDA 12 toolkit, NVIDIA driver supporting CUDA 12, Linux x86_64, ~16 GB GPU memory, network access to Hugging Face.
uv venv && source .venv/bin/activate
uv pip install "nemo-curator[text_cuda12]"
python tutorials/quickstart.pyVideo and audio pipelines depend on system codec libraries; the published container ships them preconfigured.
- Container: nemo-curator on NGC
- Setup instructions: Installation Guide
Full setup for all paths: Installation Guide • Tutorials
NeMo Curator powers the data pipelines behind NVIDIA Nemotron models. The Nemotron-4 pre-training dataset was curated using NeMo Curator's text pipeline across 8+ trillion tokens of multilingual web data — quality filtering, deduplication, and domain classification at scale.
The Nemotron-CC curation pipeline uses NeMo Curator end-to-end — from Common Crawl extraction through language ID, exact/fuzzy/substring deduplication, ensemble quality classification, and LLM-based synthetic data generation — to reproduce the Nemotron-CC datasets. The SDG stage is available as an in-repo tutorial.
NeMo Curator leverages NVIDIA RAPIDS™ (cuDF, cuML, cuGraph) with Ray to scale across multi-node, multi-GPU environments. Numbers below are from the throughput study published in the scaling docs; see the source for full methodology, software versions, and baselines.
| Metric | Workload | Hardware | Baseline | NeMo Curator |
|---|---|---|---|---|
| Fuzzy dedupe speedup | RedPajama v2 subset | 3× H100 80 GB nodes | CPU-based alternative | 10.7 h → 0.65 h (~16×) |
| Total cost of ownership | RedPajama v2 subset | 3× H100 80 GB nodes | CPU-based alternative | $315 → $190 (~40% lower) |
| GPU scaling (1→4 nodes) | RedPajama v2 subset | 1, 2, 4 × H100 80 GB nodes | Single-node run | 2.05 h → 1.01 h → 0.50 h |
Token counts and exact subset sizes vary across published panels; treat per-panel labels in the source as authoritative.
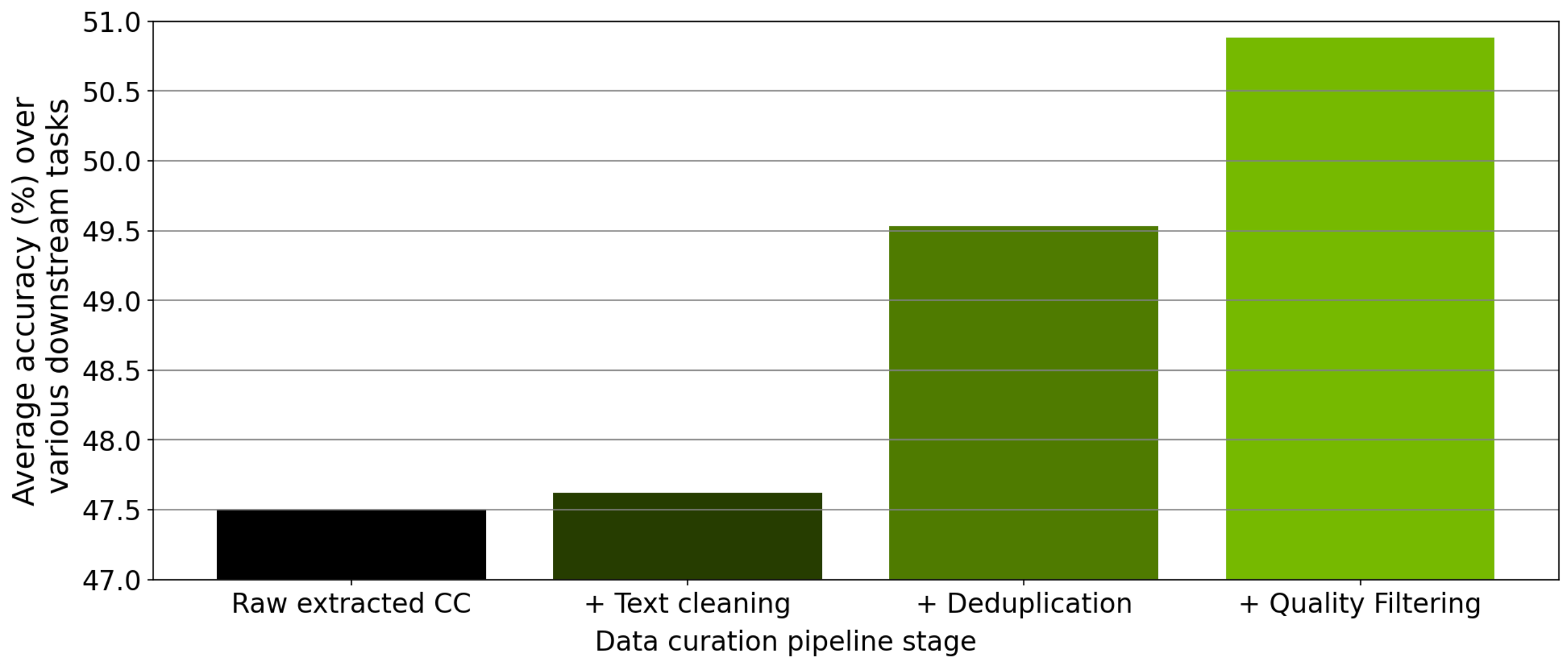
In ablation studies using a 357M-parameter GPT model trained on curated Common Crawl data, NeMo Curator's pipeline stages — text cleaning, deduplication, and quality filtering — produced progressive improvements in zero-shot downstream task accuracy.
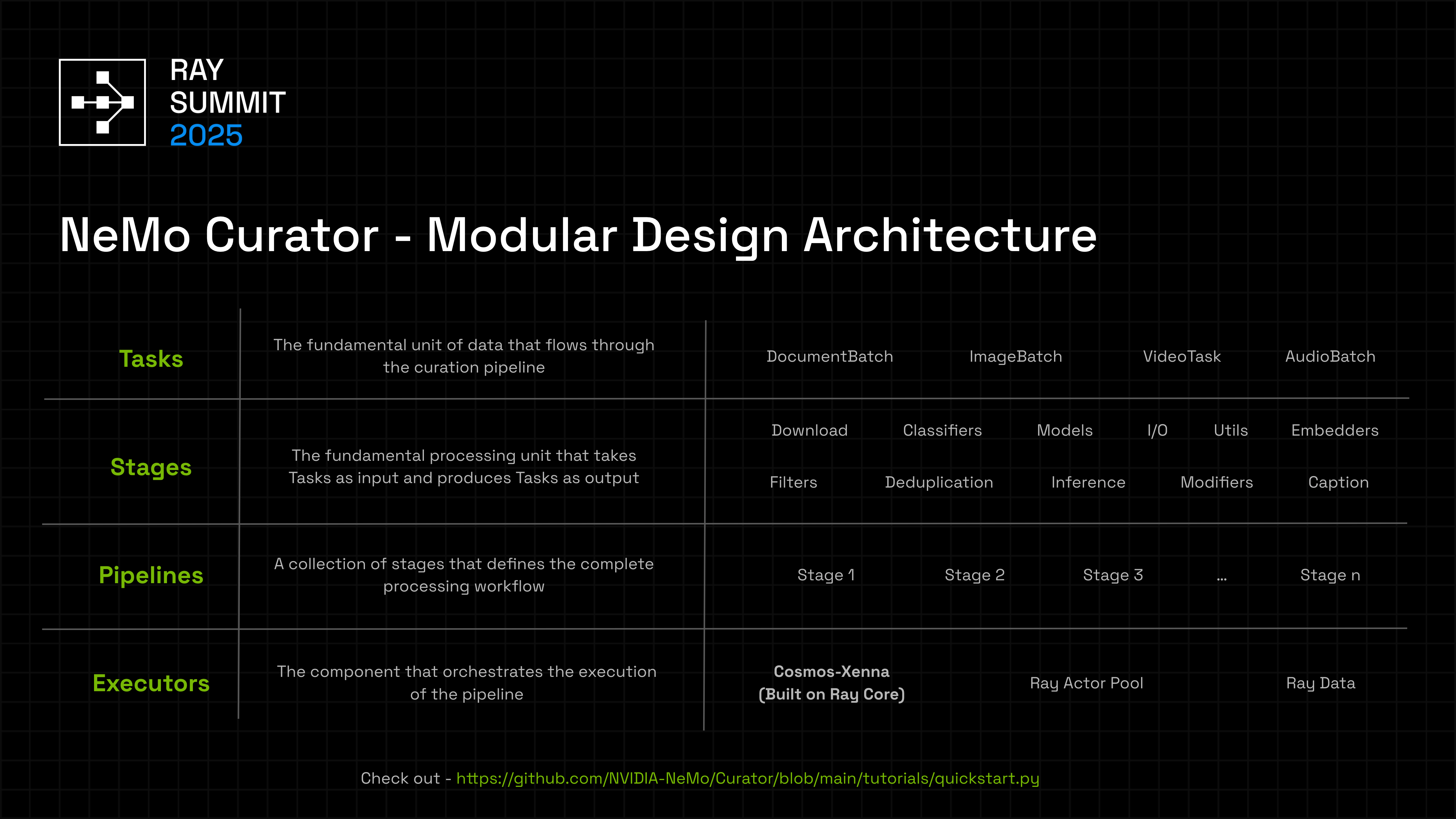
NeMo Curator pipelines are composed of stages, each handling a discrete curation task (load, filter, dedupe, classify, transform, write). Stages stream tasks through the pipeline and are executed by a pluggable executor.
- Stages declare their own resource requirements (CPU cores, GPU memory, replicas).
- Pipelines chain stages; the executor auto-scales replicas per stage to match throughput across the chain.
- Streaming execution overlaps CPU and GPU work so all stages run concurrently — typical pipelines keep GPU workers >99% busy after warm-up.
- Executors run the pipeline: the XennaExecutor (Cosmos-Xenna) is the production default, with experimental Ray-based backends also available — same pipeline definition, different runtime.
- Modality plug-ins (text, image, video, audio) provide ready-made stages on top of the same core abstractions.
See the scaling concepts for an end-to-end walkthrough.
| Recipe | What it does |
|---|---|
| Nemotron-CC end-to-end | Reproduces the Nemotron-CC dataset from Common Crawl |
| Nemotron-CC SDG | Synthetic data generation stage as an in-repo tutorial |
| Text tutorials | Loading, filtering, dedupe, classification |
| Image tutorials | WebDataset loading, CLIP embeddings, aesthetic/NSFW filtering |
| Video tutorials | Scene detection, clipping, motion filtering, dedupe |
| Audio tutorials | ASR transcription, WER filtering, multimodal handoff |
| Resource | Link |
|---|---|
| Installation guide (CPU, GPU, Docker, source) | docs.nvidia.com/nemo/curator/latest/get-started/installation |
| Container image | nemo-curator on NGC |
| Infrastructure (Slurm, Kubernetes, multi-node) | Infrastructure docs |
| API reference | API docs |
| Concepts | Concepts |
Supported Python and dependency versions are defined in pyproject.toml; the Python versions are also shown on the PyPI badge above. The README does not duplicate them to avoid drift.
Shipped changes are documented in the release notes. Planned work and feature direction are tracked in GitHub Issues and Discussions.
Pick the channel that matches your need — these are community channels staffed on a best-effort basis; there is no SLA.
| You want to… | Channel | Typical response |
|---|---|---|
| Ask a usage question, share a recipe, get design feedback | GitHub Discussions | A few business days |
| Report a reproducible bug or regression | GitHub Issues — use the bug template | A few business days for triage |
| Request a feature or new modality capability | GitHub Issues — use the feature-request template | Triaged into a milestone when accepted |
| Read the docs | docs.nvidia.com/nemo/curator/latest | — |
Please do not use Issues for "how do I…" questions — they belong in Discussions so they remain searchable for other users.
Contributions are welcome — bug fixes, docs, tutorials, new stages, and tests. See CONTRIBUTING.md for the full guide, including how to pick a good first issue, set up your environment, and open a signed-off PR. All participants are expected to follow our Code of Conduct.
NeMo Curator is released under the Apache License 2.0. See LICENSE for the full text.
If you use NeMo Curator in your research, please cite:
@misc{nemo_curator,
title = {NeMo Curator: GPU-Accelerated Data Curation for Training AI Models},
author = {NVIDIA},
year = {2024},
url = {https://github.com/NVIDIA-NeMo/Curator}
}For the data curation pipeline behind Nemotron models, please also cite:
@article{parmar2024nemotron4,
title = {Nemotron-4 15B Technical Report},
author = {Parmar, Jupinder and Satheesh, Shrimai and others},
journal = {arXiv preprint arXiv:2402.16819},
year = {2024}
}