{kind=link}
![]()
![]()
Cluster Analysis with Resampling for Validation and Exploration
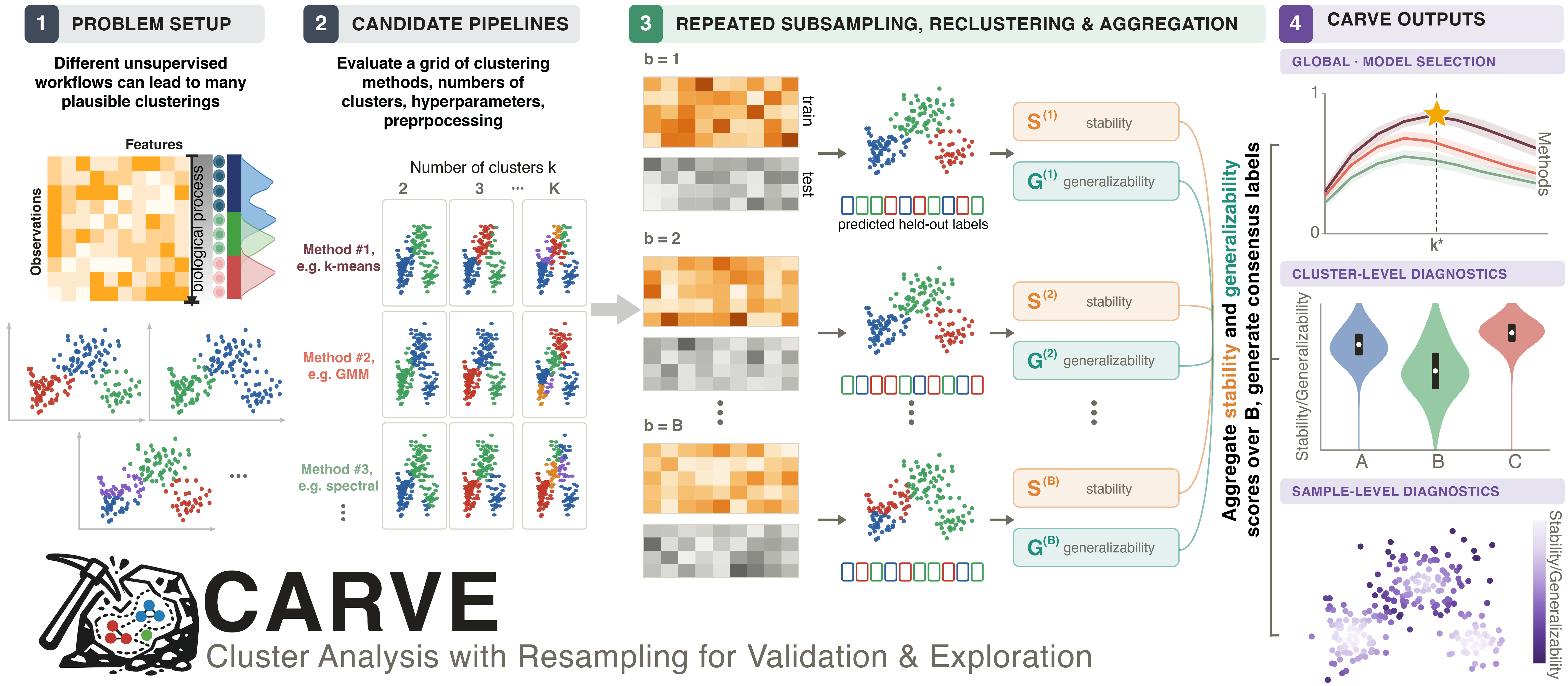
Choosing the number of clusters is hard, especially for high-dimensional biological data where standard internal clustering validation indices (CVIs) are often unreliable. CARVE measures clustering robustness through two resampling-based concepts: stability (reproducibility of cluster assignments under data subsampling) and generalizability (agreement between held-out cluster labels and predictions from a classifier trained on a subsample of the data). CARVE reports global, cluster-level, and sample-level diagnostics with visualizations, all through a scikit-learn-compatible API.
- Scikit-learn-compatible API:
CARVEextendsBaseEstimatorwith afit/get_labels/get_kworkflow - Stability (ARI on subsample overlap) and generalizability (ARI on held-out predictions) metrics
- Diagnostics at the global, per-cluster, and per-sample level
- Metrics: stability and generalizability ARIs, consensus PAC, Gini, cross-entropy, and predictive accuracy
- Selection rules:
max,1se(one-standard-error), andquantile - Custom spectral clustering with self-tuning affinity (based on Zelnik-Manor & Perona, Self-Tuning Spectral Clustering, NeurIPS 2004)
- Plots: metric-over-k curves, consensus heatmaps, box plots, violin plots, and scatter plots
- Parallel resampling via joblib (
n_jobs)
CARVE requires Python 3.12.
pip install carve-validateThe distribution is named carve-validate; the import name is carve:
from carve import CARVEgit clone https://github.com/DataSlingers/CARVE.git
cd CARVE
pip install -e ".[dev]" # linting + testing
pip install -e ".[notebooks]" # Jupyter, Scanpy, scVI, etc.from carve import CARVE
from sklearn.datasets import make_blobs
# Generate synthetic data
X, y_true = make_blobs(n_samples=500, n_features=10, centers=5, random_state=42)
# Fit CARVE
carve = CARVE(n_clusters=10, n_resamples=120, subsample_ratio=0.7, n_jobs=4)
carve.fit(X)
# Select best k and retrieve labels
k = carve.get_k(measure="generalizability", rule="1se")
labels = carve.get_labels(measure="generalizability", rule="1se")
print(f"Selected k={k}")See notebooks/Tutorial.ipynb for a walkthrough, and notebooks/case_studies/ for real-world analyses on scRNA-seq and mass cytometry datasets.
# Metric curves across k
carve.plot_metric_over_n_clusters(measure="stability", rule="1se")
# Consensus heatmap for the selected solution
carve.plot_consensus_matrix(measure="generalizability", rule="1se")
# Per-cluster stability violin plot
carve.plot_cluster_violin(source="gini", measure="generalizability", rule="1se")
# 2D scatter with score-encoded marker size and opacity
carve.plot_cluster_scatter(source="gini", measure="generalizability", rule="1se")All plotting methods return a matplotlib Axes object and accept save and dpi parameters for export.
If you use CARVE in your research, please cite:
Wycik, K. R., Tang, T. M., Zikry, T. M., & Allen, G. I. (2026). CARVE: Cluster Analysis with Resampling for Validation and Exploration. Zenodo. https://doi.org/10.5281/zenodo.20448965
@software{wycik2026carve,
author = {Wycik, Kai R. and Tang, Tiffany M. and Zikry, Tarek M. and Allen, Genevera I.},
title = {{CARVE}: Cluster Analysis with Resampling for Validation and Exploration},
year = {2026},
publisher = {Zenodo},
doi = {10.5281/zenodo.20448965},
url = {https://doi.org/10.5281/zenodo.20448965}
}- Kai R. Wycik — Columbia University
- Tiffany M. Tang — University of Notre Dame
- Tarek M. Zikry — UNC Chapel Hill
- Genevera I. Allen — Columbia University
Contributions are welcome! Please open an issue or submit a pull request.
This project uses Ruff for linting and formatting, and pytest for testing:
ruff check src/ # lint
ruff format src/ # format
pytest -v # run tests