One brain. Every agent. Nothing forgotten.
A self-hosted personal memory layer for AI agents. SQLite (or Postgres) + MCP + Ollama.
Zero-config by default; one file holds your memories, wiki, and code graph.
Your context, always available.
• Getting Started • Architecture • Philosophy • AI Providers • How To Use? • Privacy • Security • Design Decisions •
• 🌐 Site: https://baiganio.github.io/aperio •




![]()
💡 Pro Tip: Visit the Aperio Wiki or Discussions for extensive documentation on advanced topics.
🔍 Explore more: Early Testing Contributors • FAQ • Troubleshooting
📂 aperio/ <---= You are here if You are Developer. He-he ;/
├── 📂 db/
│ ├── index.js # Store factory — auto-selects Postgres or SQLite
│ ├── sqlite.js # SQLite + sqlite-vec + FTS5 adapter (zero config, default)
│ ├── postgres.js # Postgres + pgvector adapter (Docker)
│ ├── types.js # Shared DB types
│ ├── 📂 migrations/ # Postgres SQL (memories + wiki + codegraph)
│ └── 📂 migrations-sqlite/ # SQLite SQL (same schemas, FTS5 + vec0)
├── 📂 docker/
│ └── docker-compose.yml # pgvector/pgvector:pg16
├── 📂 docs/
│ └── index.html # Landing page for GitHub Pages
├── 📂 id/
│ └── whoami.md # Instructions for AI agent identity (edit this!)
├── 📂 lib/
│ ├── agent.js # Agent core — Anthropic / DeepSeek / Ollama loops
│ ├── terminal.js # Terminal chat client
│ ├── 📂 emitters/ # CLI and WebSocket stream emitters
│ ├── 📂 handlers/ # Attachment and memory handlers
│ ├── 📂 helpers/ # Embeddings, logger, port, shutdown, Ollama health
│ ├── 📂 routes/ # Express API routes + path safety guards
│ ├── 📂 utils/ # Chat utilities
│ └── 📂 workers/ # Deduplication, reasoning adapters, skill loader
├── 📂 lib/codegraph/ # Pre-indexed code knowledge graph (symbols, calls, imports)
│ ├── indexer.js # Backend dispatcher (Postgres or SQLite)
│ ├── watcher.js # chokidar-backed live reindex
│ ├── extract-ts.js # tree-sitter JS/TS/JSX/TSX extractor
│ └── 📂 backends/ # postgres.js · sqlite.js
├── 📂 mcp/
│ ├── index.js # MCP server entry point
│ └── 📂 tools/
│ ├── memory.js # remember · recall · update_memory · forget · backfill_embeddings · deduplicate_memories
│ ├── codegraph.js # code_search · code_outline · code_context · code_callers · code_callees · code_repos
│ ├── files.js # read_file · write_file · append_file · scan_project
│ ├── shell.js # run_node_script · run_shell · syntax_check
│ ├── web.js # fetch_url
│ └── image.js # read_image · preprocess_image
├── 📂 public/
│ └── index.html # Web UI — themes, streaming, sidebar
├── 📂 skills/ # Memory, reasoning, tools, coding standards, etc.
├── 📂 tests/
├── .env.example # Pre-set quick configuration
├── package.json # Dependencies
└── server.js # Express + WebSocket + agent loop
💡 Tip:
whoami.mdcontrols the identity of the AI agent.
- It is the most impactful file to customize.
- Node.js 18+ — download from https://nodejs.org/en/download
- Docker Desktop — (optional, for Postgres mode)
- Ollama — download from https://ollama.com/download (optional, for local AI)
- Anthropic API key — (optional, for cloud AI)
- DeepSeek API key — (optional, for cloud AI)
- Google Gemini API key — (optional, for cloud AI)
- Voyage AI API key — (optional, for cloud embeddings)
Dedicated dev branch stripped from the file/folder noise. Only what's needed.
# dedicated developer branch - no extra files
git clone --depth 1 -b dev https://github.com/BaiGanio/aperio.git
cd aperio
# restore dependencies
npm installReady to use
.env.examplefor a fully local setup:
# cp .env.example .env
AI_PROVIDER=ollama
OLLAMA_MODEL=qwen3:4b
EMBEDDING_PROVIDER=transformers # fully local, no API key required
# DB_BACKEND=sqlite # default; uncomment to override
# SQLITE_PATH=./var/aperio.db # default location for the single-file DBAperio supports two storage backends. You don't need to choose — auto-detect picks the right one based on whether Docker is running:
| Backend | When to use | Requires |
|---|---|---|
| SQLite + sqlite-vec (default) | No Docker, quick start, single user. Single file at var/aperio.db. |
Nothing extra |
| Postgres + pgvector | Multi-agent, persistent, production-like | Docker |
# SQLite is the default — no extra steps needed.
# Skip the Docker commands below and go directly to Step 3.💡 Tip: Set
DB_BACKEND=sqlitein.envto force SQLite, orDB_BACKEND=postgresfor Postgres.
If not set, Aperio auto-detects: uses Postgres when Docker is running, SQLite otherwise.
# POSTGRES MODE — start the database and run migrations
cd docker && docker compose up -d && cd ..
npm run migrate💡 Tip: Skip this step entirely if you are using Anthropic or DeepSeek as your
AI_PROVIDER.
ollama serve # use separate terminalollama pull qwen3:4b # LLM — strong reasoning, thinking mode, best tool-calling
# ollama pull qwen2.5:3b # LLM — lightweight legacy fallback
# ollama pull llama3.1 # LLM — solid tool-calling, no reasoningnpm run start:local # localhost:31337 → browser opens automaticallynpm run chat:local # runs as proxy or standaloneThat's it. No API keys. No cloud. Full semantic memory on your machine.
💡 Stuck on the installation steps? — check Troubleshooting wiki.
💡 Check Aperio MCP Tools Guide wiki for extended examples.
💡 Check Commands wiki for the available options to run the app.
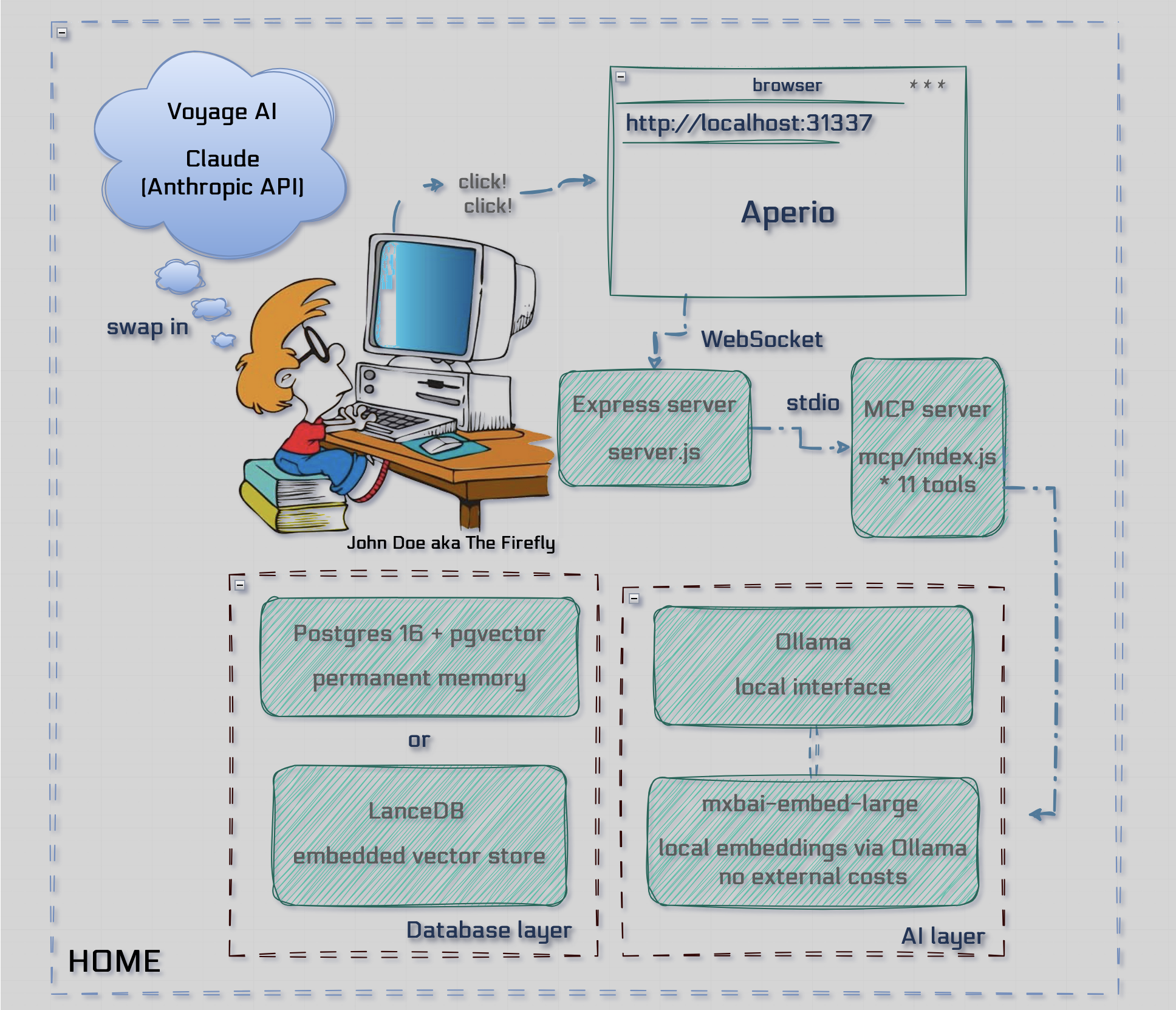
💡 Tip: Visit Architecture & Design for in-depth explanations.
Aperio can boot a second agent alongside the primary so that any chat turn
can be cross-reviewed before it reaches you. Two agents take turns: Agent A
answers, Agent B reviews, A revises, B re-reviews — until they reach
explicit AGREED or a hard round cap is hit. A single consensus bubble is
rendered when they agree; otherwise both positions are shown side-by-side.
Enable it with ROUNDTABLE_AGENTS in .env:
# Format: provider:model,provider:model
ROUNDTABLE_AGENTS=anthropic:claude-haiku-4-5-20251001,deepseek:deepseek-chat
ROUNDTABLE_MAX_ROUNDS=3When set, the chat UI gains a Discuss toggle next to the send button.
Toggle it ON to route the next turn through the round-table; OFF behaves
identically to single-agent chat. If ROUNDTABLE_AGENTS is unset or only one
pair parses, the toggle stays disabled and the app behaves exactly as before.
Personas live in id/whoami-primary.md and id/whoami-verifier.md — edit them
to tune how each agent answers or critiques.
Aperio ships a pre-indexed code knowledge graph so an agent can query
your codebase instead of reading 50 files to answer "who calls X?" or
"where is Y defined?". Symbols, calls, imports, and extends edges are
extracted with tree-sitter (JS / TS / JSX / TSX) and stored alongside
your memories.
Two ways to use it:
# 1. One-shot index of the current directory
node lib/codegraph/indexer.js .
# 2. Live mode — start the server with a file watcher that reindexes on save
APERIO_CODEGRAPH=on npm run start:localThe graph respects APERIO_ALLOWED_PATHS_TO_READ, so you can index
multiple repos at once (e.g. Aperio + a side project). The sidebar in
the web UI has a "Code" panel for searching symbols and walking
callers / callees visually; the model uses the same data via the
code_* MCP tools listed below.
Backend support: Postgres and SQLite both work. With SQLite (the
default), the graph lives in the same var/aperio.db file as your
memories.
Aperio exposes 28 tools over MCP. Any MCP-compatible agent (Cursor, Windsurf, Claude, etc.) can call them.
| Category | Tool | What it does |
|---|---|---|
| Memory | remember |
Save a memory with type, title, tags, importance, and optional expiry |
recall |
Semantic or full-text search across all memories | |
update_memory |
Update an existing memory by ID; tombstones the old version, re-generates its embedding | |
forget |
Delete a memory by ID | |
backfill_embeddings |
Generate embeddings for memories that are missing one | |
deduplicate_memories |
Find and merge near-duplicate memories by cosine similarity | |
| Wiki | wiki_write |
Create or update a wiki article (LLM-authored, cited synthesis); upserts by slug, bumps revision |
wiki_search |
Hybrid full-text + semantic search over articles — call before wiki_write |
|
wiki_list |
Browse articles newest-first by tag / status / updated_since |
|
wiki_get |
Fetch a full article by slug, with breadcrumb and optional stale-refresh | |
| Code Graph | code_search |
Hybrid FTS + semantic search over pre-indexed symbols (functions, classes, methods, consts) |
code_outline |
List every symbol in a file by line — cheap map before reading | |
code_context |
Fetch the source slice for a qualified symbol, with leading doc and line padding | |
code_callers |
Walk the reverse call graph (depth-capped) — who calls this? | |
code_callees |
Walk the forward call graph (depth-capped) — what does this call? | |
code_repos |
List indexed repos with file / symbol counts and last-indexed timestamp | |
| Files | read_file |
Read a code or text file (max 500 lines per call, paginated via offset) |
write_file |
Create or overwrite a file (subject to write-path guard) | |
append_file |
Append content to an existing file without touching the rest | |
edit_file |
Replace an exact string in a file (replace_all for multiple occurrences) |
|
scan_project |
Traverse a project folder — returns a file tree and reads key files | |
generate_xlsx |
Generate a multi-sheet .xlsx workbook, served for download |
|
| Shell | run_node_script |
Run a .js script inside an allowed write path; returns its output |
syntax_check |
Check a JavaScript file for syntax errors without executing it | |
| Web | fetch_url |
Fetch a URL, strip HTML, truncate at 15 000 characters |
| Image | read_image |
Load an image (file path or base64) for the agent to analyze |
preprocess_image |
Normalize an image to RGB PNG before sending to a local VLM (strips alpha, letterboxes to 896×896) | |
describe_image |
Send an image to a local Ollama vision model (VLM) and return a text description |
PowerPoint files are generated by writing a script (see
skills/pptx/) and running it viarun_node_script— there is no dedicatedpptxtool.
💡 Tip: Check Aperio MCP Tools Guide for call examples.
Aperio is open source and self-hosted because your memories is yours.
- It runs entirely on your machine - no API keys, no data leaving your network, no cloud dependency.
- Default is local and private. The option - self-hosted. The price - free forever.
- Cloud AI is available as a power upgrade, but you will be never forced to use it.
| 🔒 Local by default | ☁️ Cloud as upgrade |
| Ollama + local embeddings — zero external calls | Claude / DeepSeek for deep research & heavy tasks |
| 🗄️ Your brain, your data | 🖥️ MCP-native |
| Postgres or SQLite lives on your machine. You own it. | Any MCP agent plugs in — Cursor, Windsurf, etc. |
| ✅ Free to run |
| No subscription. No per-message cost. Just your hardware. |
Deployment model:
| 🚫 Not a cloud service | 🚫 Not a managed product |
| No hosted version, no SaaS, no managed infra | No support contracts, SLAs, or guaranteed uptime |
| 🚫 Not plug-and-play | 🚫 Not production-hardened |
| Needs Node.js and basic terminal comfort | Early software, built in the open, improving fast |
Feature scope — what Aperio will never become:
| 🚫 Not a chat app | 🚫 Not a general-purpose AI agent |
| The bundled Web UI and terminal client are conveniences for setup and inspection — not the product. Aperio is an MCP server first. | Aperio provides memory, wiki, and code-graph tools TO agents. It does not replace the agent itself. |
| 🚫 Not a replacement for Claude, Cursor, or Windsurf | 🚫 Not a multi-tenant SaaS platform |
| Aperio is a memory layer that sits alongside your existing AI tools. It augments them — it does not compete with them. | Single-user, single-machine by design. No accounts, no organizations, no billing system. Will stay that way. |
| 🚫 Not a plugin or extension | 🚫 Not a "build everything" platform |
| It's a self-hosted server you run yourself — not something you install into another app. | Aperio says no to feature ideas that dilute the core: memory + code graph for MCP agents. If a feature doesn't serve that sentence, it doesn't ship. |
Switch with a single line in .env. Everything else — memories, tools, UI — stays identical.
AI_PROVIDER=ollama # "ollama" | "anthropic" | "deepseek" | "gemini"No API keys, no data leaving your machine.
AI_PROVIDER=ollama
OLLAMA_MODEL=qwen3:4b
OLLAMA_BASE_URL=http://localhost:11434Recommended models (pull with ollama pull <model>):
| Model | Best for |
|---|---|
qwen3:4b |
Default — strong reasoning, thinking mode, best tool-calling |
llama3.1 |
Solid tool-calling, no thinking/reasoning overhead |
qwen2.5:3b |
Legacy — lightweight, good for ≤ 8 GB RAM |
deepseek-r1:32b |
Heavy reasoning, requires ≥ 60 GB RAM |
💡 Tip: Set
CHECK_RAM=truein.envto let Aperio auto-select a model based on available RAM.
For heavy research, complex multi-step reasoning, or the strongest tool-calling available.
AI_PROVIDER=anthropic
ANTHROPIC_API_KEY=sk-ant-...
ANTHROPIC_MODEL=claude-haiku-4-5-20251001Available models (set via ANTHROPIC_MODEL):
| Model | Notes |
|---|---|
claude-haiku-4-5-20251001 |
Fast and cost-efficient — good default |
claude-sonnet-4-6 |
Balanced performance and cost |
claude-opus-4-7 |
Most capable, highest cost |
Cost-effective cloud alternative with strong reasoning capabilities.
AI_PROVIDER=deepseek
DEEPSEEK_API_KEY=sk-...
DEEPSEEK_MODEL=deepseek-chatSign up at platform.deepseek.com. No vision support — image tools are disabled in DeepSeek mode.
Large context window with native vision support.
AI_PROVIDER=gemini
GEMINI_API_KEY=...
GEMINI_MODEL=gemini-2.0-flashGet a key from aistudio.google.com.
Embeddings power semantic search across your memories. Aperio supports two providers:
EMBEDDING_PROVIDER=transformers # "transformers" | "voyage"Downloads mixedbread-ai/mxbai-embed-large-v1 (ONNX, quantized) on first run. No daemon, no API key, no network calls after the initial download.
EMBEDDING_PROVIDER=transformersHigher-quality embeddings, free tier: 50M tokens/month.
EMBEDDING_PROVIDER=voyage
VOYAGE_API_KEY=pa-...Sign up at dash.voyageai.com.
💡 Tip: Check out our wiki pages AI Agents Comparison & Embeddings for more details.
Ollama itself has no file system access — it's purely an inference engine. Aperio's MCP layer bridges the gap.
When you ask the AI to read a file, here's what actually happens:
You → "read /path/to/server.js and explain the WebSocket handler"
MCP Server → calls read_file tool, loads the file from disk
Ollama → receives the file contents as context, reasons over it
You ← answer based on your actual code
The model never touches your file system directly. Aperio reads the file and injects the content into the conversation.
💡 Check out our wiki page MPC Tools for more details.
Aperio runs on your machine and has access to your file system through the scan_project, write_file, append_file, and read_file tools. File operations are gated by a path safety system — read and write access are controlled independently.
All file operations go through lib/routes/paths.js, which resolves and validates every path before it reaches the disk.
Two environment variables control what is accessible:
# Allow read operations only inside these directories (comma-separated absolute paths)
APERIO_ALLOWED_PATHS_TO_READ=/Users/yourname/projects,/Users/yourname/documents
# Allow write operations only inside these directories (comma-separated absolute paths)
APERIO_ALLOWED_PATHS_TO_WRITE=/Users/yourname/projectsHow path resolution works:
- Both values default to the current working directory (
process.cwd()) when not set — which is the Aperio project root when you runnpm run start:local. - Paths are resolved to absolute form at startup.
~is expanded to the working directory. - A request to read or write
/some/path/file.txtis allowed only if its resolved absolute path starts with one of the permitted directories. Paths outside the allow-list are rejected with a clear error message before any I/O occurs. - Read and write guards are separate. You can grant broad read access while keeping write access narrow — for example, read your entire
~/projectstree but only write inside the Aperio project root.
What the model can and cannot do:
| Operation | Guard | Default scope |
|---|---|---|
read_file |
APERIO_ALLOWED_PATHS_TO_READ |
Project root |
write_file |
APERIO_ALLOWED_PATHS_TO_WRITE |
Project root |
append_file |
APERIO_ALLOWED_PATHS_TO_WRITE |
Project root |
scan_project |
APERIO_ALLOWED_PATHS_TO_READ |
Project root |
Additionally, read_file enforces:
- Extension allow-list — only code and text files (
.js,.ts,.py,.md,.json,.sql,.sh, etc.) - Size cap — files larger than 500 KB are rejected
- Pagination — reads at most 500 lines per call; use the
offsetparameter to page through larger files
By default the model can only execute .js files (the run_node_script tool). The optional run_shell tool widens this to a fixed allow-list of real binaries — used for QA steps that need them, such as pptx visual QA (soffice → pdftoppm) or grepping extracted text for leftover placeholders. It is off by default and gated by two environment variables.
⚠️ Trust level: enablingrun_shellgrants the model full host-level command execution as your user — it is not a sandbox. The allow-list constrains which programs run and their arguments (no interpreter inline-eval likenode -e/python3 -c, nofind -exec, read-onlygit, file arguments confined to allowed paths,curlremoved in favour of the SSRF-guardedfetch_url), but a determined model with shell access still operates with your privileges. Only enable it for models and content you trust.
# Master switch — enables run_shell at all. When unset, the tool refuses every call.
APERIO_ENABLE_SHELL=1
# Opt-in for LOCAL Ollama models. Cloud providers (Anthropic/Gemini/DeepSeek) get
# run_shell as soon as the master switch is on; local models stay node-only unless
# you also set this, since smaller local models are prone to tool-call thrashing.
APERIO_SHELL_LOCAL=1Constraints, enforced in mcp/tools/shell.js:
| Guard | Behavior |
|---|---|
| Allow-list | Only node, npm, git, ls, cat, grep, rg, find, head, tail, python3, soffice, pdftoppm run |
| Operators | ;, &&, ||, &, <, >, backticks, $() are rejected; a single | pipe is permitted |
| Working dir | Commands run in the active session workspace (or an explicit cwd within an allowed write path) |
| Limits | 60 s timeout, 200 KB output cap (shared with run_node_script) |
| Per-model gate | Disabled providers/models never see the tool at all (see isShellAllowedFor in lib/agent/index.js) |
📄 Take a notes:
- Only run Aperio on a machine you trust
- Do not expose the MCP server or web UI to the public internet without authentication
- Review any file write operations before confirming them —
write_fileoverwrites completely with no undo - The AI model can be prompted (or hallucinate) to write to sensitive paths — always review before confirming
- Never commit your
.envfile — it contains your database URL and API keys - Write paths should be equal to or a strict subset of read paths
💡 Check out our wiki page Path safety for more details.
One brain. Every agent. Nothing forgotten.
From Latin aperire — to open, to reveal, to bring into the light.